Theory
Random forests are essentially a collection of decision trees. Each tree is built with a random sample of our data. Each tree generates a prediction and the most popular classification is then chosen from the resulting trees.
The goal of random forests, just like decision trees is to minimise entropy. Entropy is a measure of uncertainty associated with our data. This can be represented mathematically by the following equation where x is the percent of the group that belongs to a certain class and H is the entropy.
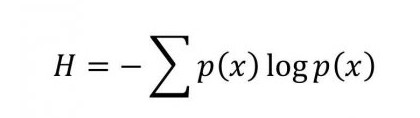
We need to minimise entropy. We use information gain to determine the best split. Information gain is calculated by the following equation:
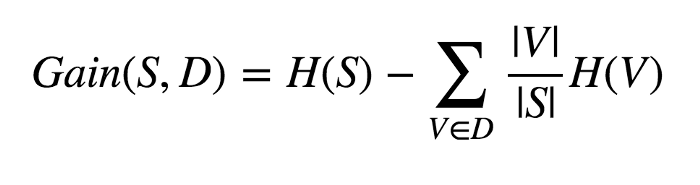
The Information gain is just the original Entropy of the data before the split H(S), minus the sum of the weighted split entropy values. S is the original set and D is the splitting of the set (a partition). Each V is a subset of S. All of the V’s are disjoint and make up S.
A good article on them explaining their theory can be found here.
This is where I uncovered the following logic.