PROCESSING
Instead of being selective about our columns in our models we can just drop the ones which are redundant now.
Feature Engineering
Notice that the area column as categorical
That means we need to transform them using dummy variables so sklearn will be able to understand them. Let's do this in one clean step using pd.get_dummies.
Let's show you a way of dealing with these columns that can be expanded to multiple categorical features if necessary.
Create a list of 1 element containing the string 'purpose'. Call this list cat_feats.
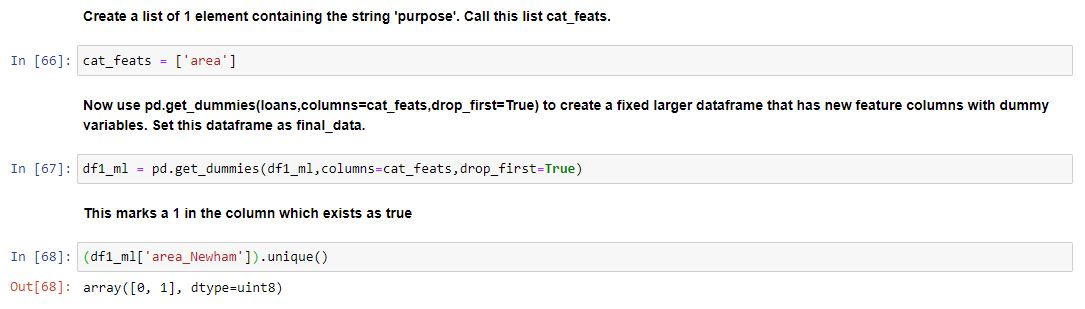
Our areas are now turned into columns with a one representing TRUE.